Since OpenAI released the first Generative Pre-Trained Transformer (GPT-1) in June 2018, the growth of AI has been exponential. More parameters. More models. More computational resources. More data centers. To keep up with recent advancements, you need to sprint just to stand still. This is the norm of 2026 and beyond.
But amid all this change, one thing remains constant: data. It is the backbone of progress, the fuel to the fire, and in a hypercompetitive environment, the edge that separates winners from the rest.
The Model Explosion
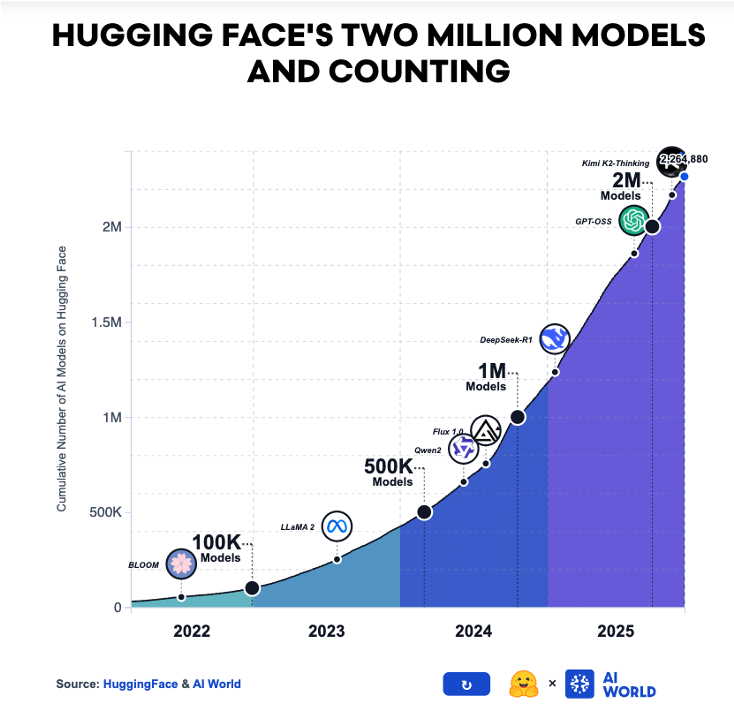
On Hugging Face, one of the leading platforms for open-source AI collaboration, the number of models has grown to over 2 million. In just three years, that's a factor of 20x.
Why does this matter? In data science and AI, a model is a mathematical representation attempting to capture the underlying relationships within a dataset. A more sophisticated model can yield better performance. Historically, proprietary modeling techniques provided real competitive advantages.
That era is ending. With this open-source explosion, there is now a plethora of ideas to iterate on. Continuously fewer techniques remain hidden from the broader community. The technical gap between firms, once a defining edge, is now as small as it has ever been, with no sign of growing.
The Coding Barrier Has Collapsed
Five or so years ago, the democratization of models wouldn't have mattered as much. The technical skill required to understand these models, implement the code, test them, and push to production commanded a premium.
That premium has evaporated.
With the emergence of CLI-based autonomous coding agents like Claude Code, the technical barrier has all but disappeared. Any analyst, regardless of coding background, can now implement sophisticated machine learning pipelines without writing a single line of code. They can prompt an entire training cycle, fine-tune an LLM from scratch, and deploy it to production.
There is nuance here: understanding the underlying code before deploying it still matters. But the broader point stands. A firm with the deepest pockets could once hire the most technically sound developers and maintain a significant advantage in model sophistication. That barrier to entry is eroding with each new iteration of large language models.
AI Adoption Is Now Table Stakes
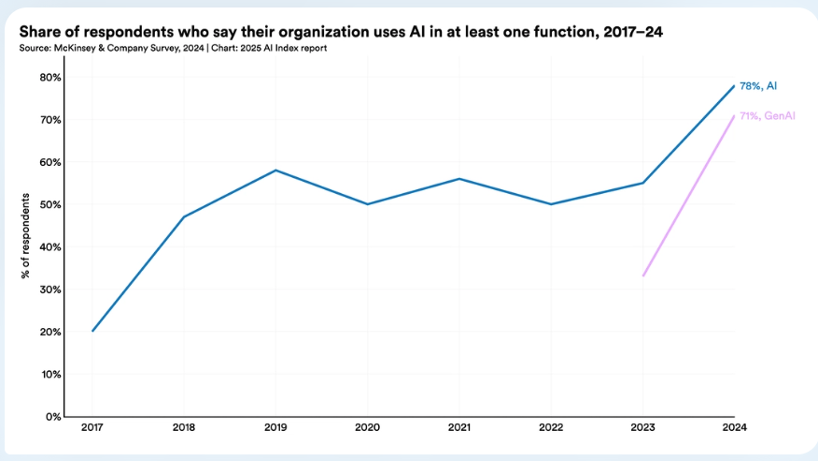
According to McKinsey, over 70% of organizations reported using at least one generative AI function in 2024. By 2026, I suspect this number will approach 100%.
The implication is clear: most organizations are now leveraging the same tools, with access to the same world-class researchers and developers, as AI assistants, if not as employees. What was once a differentiator is now a prerequisite.
The Implications for Quantitative Hedge Funds
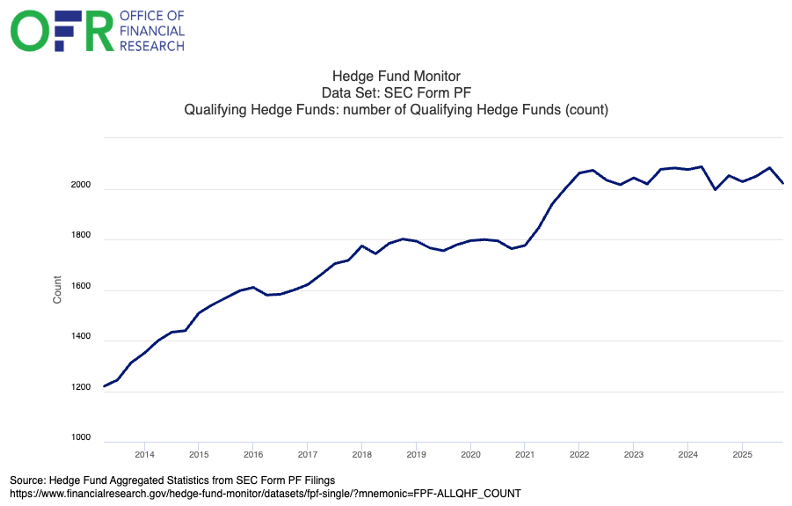
Nowhere is this dynamic more apparent than in quantitative finance. According to SEC Form PF filings, the number of Qualifying Hedge Funds (those with at least $500 million in net assets) has nearly doubled over the past decade plus. Competition is intensifying in an already lucrative industry.
Every one of these firms is most likely investing in state-of-the-art AI initiatives. But the talent gap that once existed (having the best researchers who could theorize the best strategies and write the best code) is no longer a competitive advantage. It is simply the cost of entry.
So where is the edge to be found?
The Answer: Data
With the technical gap shrinking, with more shared knowledge, with more accessible high-powered AI applications: the answer is data.
It doesn't matter how many parameters the newest large language model has. It doesn't matter how seamlessly another MCP architecture integrates. It doesn't matter how scalable cloud-based training has become. None of it matters without high-quality data.
The Alpha Erosion Problem
Here's the uncomfortable reality for quantitative firms: alpha erodes. When multiple funds apply similar models to similar datasets, the information advantage disappears. The signal gets arbitraged away. What once generated outsized returns becomes table stakes, then noise.
Traditional market data (prices, volumes, fundamentals, etc.) is available to everyone. The same Bloomberg terminal sits on every trading desk. The same SEC filings are parsed by the same algorithms. When everyone is fishing in the same pond with the same equipment, the fish get harder to catch.
The Alternative Data Opportunity
This is where alternative data enters the picture. Unstructured, unconventional, and often underutilized sources of information that sit outside the traditional financial data ecosystem.
Consider social media sentiment. Platforms like X (formerly Twitter), Reddit, and StockTwits generate millions of data points daily: real-time expressions of investor sentiment, emerging narratives, and market-moving discussions. This is not structured data waiting in a database. It's messy, noisy, and requires sophisticated processing to extract signals from noise.
At Context Analytics, this is precisely the problem we've spent over a decade solving. We transform unstructured data like social media conversations into quantified sentiment metrics (S-Scores, sentiment velocity, volume anomalies) that provide a fundamentally different lens on market dynamics. It's data that most firms don't have, can't easily replicate, and that can surface signals not reflected in traditional market data.
And here's the key point: unlike models or code, alternative data infrastructure cannot be spun up overnight. You cannot simply decide to build this in-house and expect comparable results. The value comes from years of refinement: iterating on natural language processing pipelines, filtering noise from signals, understanding the nuances of how retail investors communicate versus institutions, calibrating for market regimes and platform changes. That depth is not something a new entrant can shortcut, no matter how sophisticated their AI tools.
The edge isn't in having a better model. It's in having better inputs to the model. Inputs that took years to build and that competitors cannot easily replicate.
The New Competitive Moat
From a quantitative perspective, sustainable alpha will increasingly come from finding robust data sources that competitors don't have access to. Proprietary data pipelines. Unique alternative data relationships. The ability to process unstructured information at scale.
Models are commoditized. Talent is augmented. Compute is rented. But proprietary data? That remains scarce, defensible, and valuable.
In an AI-driven world of constant change, data is the constant.
