Social Market Analytics has extensive Intellectual Property in three distinct areas: Topic model creation, account filtering and natural language processing (NLP). I have written blog post about SMA topic model creation capabilities and the impact of our account filtering algorithms. This blog answers the question – “Do your machine learning algorithms really add value to the NLP process?”. Answer -> Yes. The chart below illustrates the statistically significant benefits of Social Market Analytics Machine Learning Algorithms in isolation.
Start date for this analysis is 11/20/2018 and the end date is 4/30/2019. This period was chosen because of the significant market draw down in December. We use dictionaries with three distinct rule sets. We use a static dictionary as of the start and end dates and compare resulting predictive returns with a point-in-time dictionary (production). Our patented NLP scores Tweets using the dictionaries at each time, S-Scores are calculated from the generated Tweet scores. The point-in-time dictionary represents word additions, phrases, and grammatical logic as they are made.
We isolate the impact of our NLP process by turning off account filtering applied to the Twitter stream. To ensure we are pulling Tweets only discussing companies and securities, we are using our topic model filtering algorithms. We regularly publish our full return charts to illustrate the impact of our entire process.
Let us start by defining the lines in our chart.
Red Line = Tweets are scored using our dictionary of words and phrases as of 11/20/2018. This illustrates the performance with no machine learning applied on a go forward basis. This is the base case. This line represents the least amount of learned information.
Black Line = Tweets are scored using words and phrases applied Point-In-Time. This is the production feed SMA customers receive. We use Supervised and Unsupervised Machine Learning. There are impacts from both during this period.
Green Line = Represents the Perfect Information scenario. Take the most up to date dictionary of words and phrases (4/30/2019) and apply them backwards. All information learned during the volatile period is included. This represents the values expected to be received on a go forward basis.
The charts below represent the cumulative Open to Close return of securities selected based on S-Score 20 minutes prior to market open. S-Score measures the tone of the current conversation relative to historical benchmarks. We select securities with an |S-Score| > 2. Securities with S-Score > 2 are purchased on the open. Securities with S-Score < -2 are sold short on the open. SMA Chart lines represent a theoretical long/short portfolio. Isolated long and short sides are available upon request.
For comparison purposes S&P 500 open to close chart for the analyzed period is below.

The chart below illustrates the cumulative O-C performance illustrating the impact of our ML algorithms. As expected, the lowest performance is the red line representing the dictionary at start date. The back line represents SMA production data and green line represents the perfect information case.
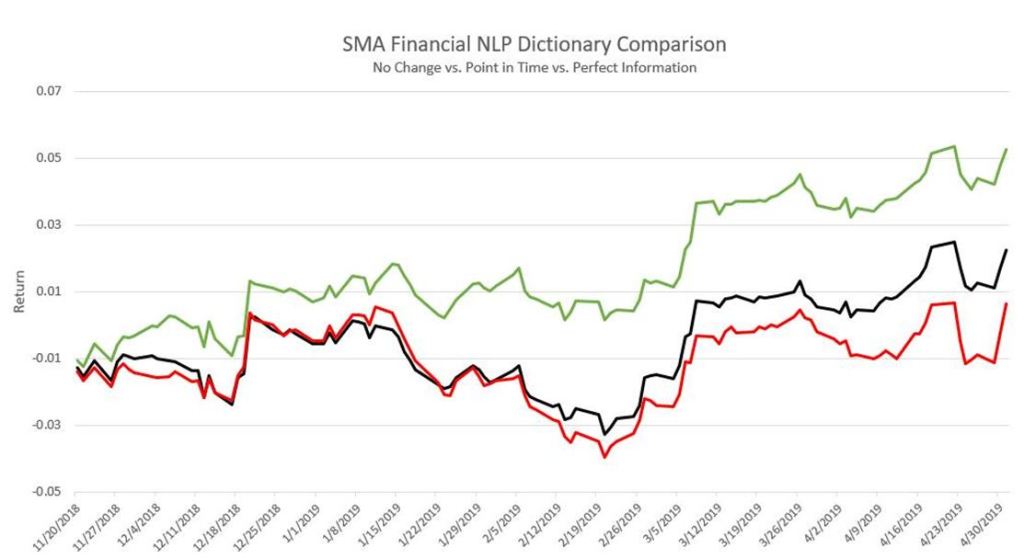
Again, this only looks at the impact of SMA NLP and does not include account filtering. At SMA we believe it’s not just what is being said but who is saying it. We employ a twelve variable algorithm to score and filter all Twitter accounts Tweeting about companies/securities to identify our approved account universe. As you can see SMA NLP is a learning system with demonstrable impact. To learn more please contact us at contactUs@SocialMarketAnalytics.com.
Thanks,
Joe