The SMA research team has done a tremendous amount of research on Machine readable filings. This Blog is taken from a research paper authored by Koby Weisman. SMA partnered with S&P Global Market Intelligence to provide textual data in U.S. SEC EDGAR filings broken down by heading with text underneath (i.e. Parts, Items). The textual data is parsed to create historical baselines for 10-Ks, 10-Qs, 8-Ks, 20-Fs and other filings. This paper focuses on word counts, sentiment factors, and the change in those factors. There are 20 filing types in the MRF product, however this paper analyzes 10-Ks and 10-Qs building on existing academic research including Lazy Prices1.
The MRF dataset includes seven factors which are described in the table below. These factors are produced at the Item, Part, and Total Document level to provide a comprehensive view of what sections within the document have changed.

Subscribers of the MRF dataset can create derivative metrics stemming from the seven factors provided. For instance, one metric explored in this paper is Sentiment per Word. That factor is calculated by dividing Sentiment Sum by Word Count. Another factor explored is Percentage of Sentiment Hits which is calculated by dividing Sentiment Hits by Word Count. These factors and other derivative factors are calculated to normalize sentiment based on the length of document.
Methodology
The MRF dataset provides word counts and sentiment factors throughout the entire document, each part, and each item of the quarterly or annual report. In order to test our hypothesis that larger changes in SEC Edgar filings underperform smaller changes, we created metrics that exemplify ‘changes’ in a report.
The authors of Lazy Prices categorized changes in filings using a variety of similarity metrics (cosine similarity, Jaccard similarity, minimum edit distance, and simple similarity). In our analysis we use raw change in word count as proxy for similarity scores. Raw change in word count is the difference between the word count in two filings. This analysis looks at the Quarter-over-Quarter changes in regulatory filings. Each 10-K and 10-Q is compared to the most recent 10-K and 10-Q from the same company.
In addition to word count, this analysis explores other factors included in the MRF dataset which contain sentiment scores, word counts categorized by sentiment, and factors that combine word counts and sentiment.
Lazy Prices makes no mention of their universe, so we used all securities over five US dollars. The benchmark used, called ‘Universe’, is the average return of all stocks in any Quintile portfolio at that point in time. The analysis begins in 2007 and concludes at the end of 2019.
When computing calendar-time portfolio returns, stocks enter buckets depending on the factor or the raw change in that factor. Stocks enter the portfolio in the month the report was released. Portfolios are rebalanced monthly to introduce new filings submitted in the most recent month. Note that average portfolio size can differ due to documents having the same value.
Results
Results below show graphs and metrics related to calendar-time portfolio returns. ‘Q1’, or Quintile 1, contains stocks with the lowest value of the factor while ‘Q5’ encompasses stocks with the highest value of the factor.
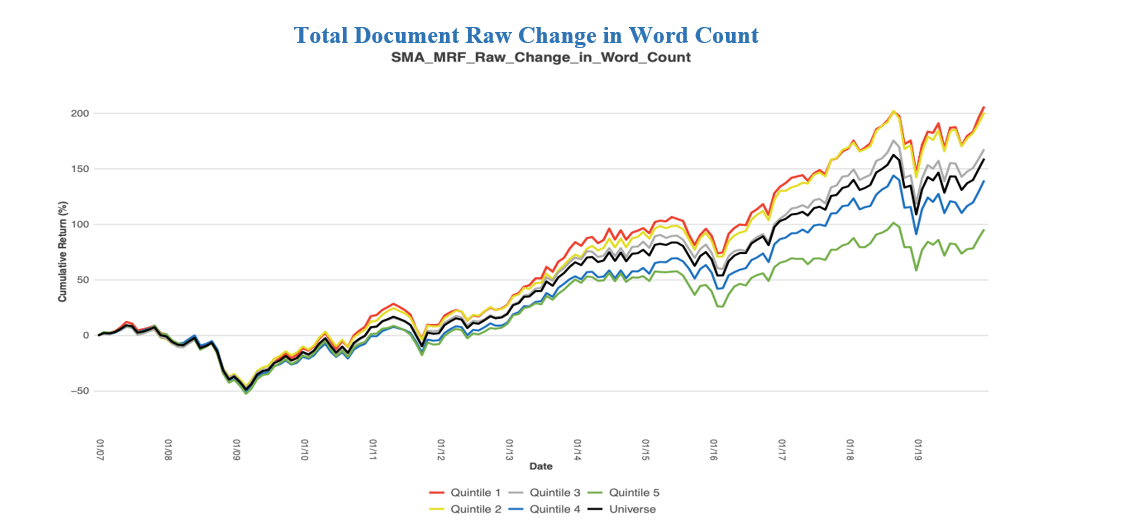
We first looked at metrics on the total document level. This contains data embedded at the Item and Part level of a regulatory filing, which is then rolled up to the document level.
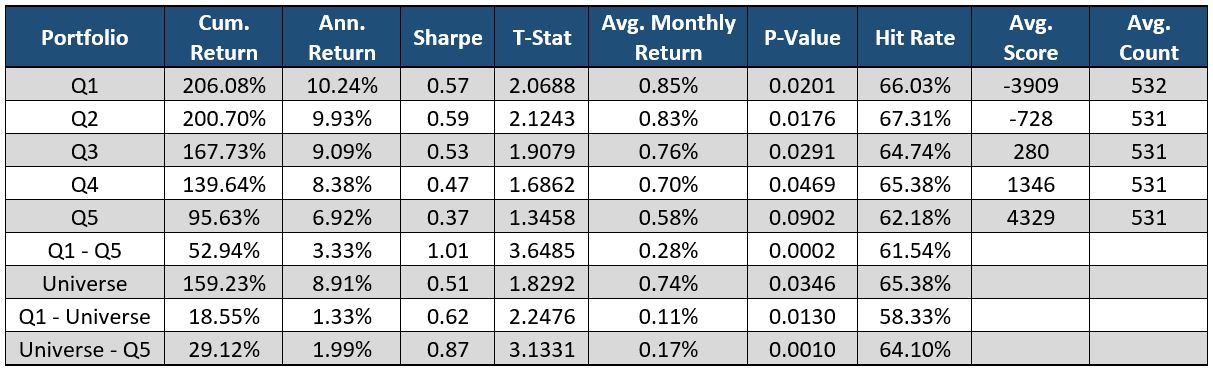
The graph and table above exemplify how Raw Change in Word Count can enhance stock selection. The green line represents securities that have the largest increase in Word Count while the red line denotes securities that have the largest decrease in Word Count. The red line, Quintile 1, outperforms all other quintiles while the green line, Quintile 5, underperforms all other quintiles.
As filings become longer or wordier compared to the company’s most previous filing, returns tend to drop compared to the universe. Regulatory filings are intended to adequately warn investors or potential investors about the company’s actions and strategies. If there are more warnings and explanations of the company’s actions, then the company isn’t as stable and thus underperforms the market.
As filings become shorter or more concise, subsequent stock returns outperform the universe. Companies that have a decrease in word count do not boast of events or products, but rather provide succinct statements. Also, one-off events that were in the company’s previous regulatory filing are taken out of the document meaning that the event was resolved.
The difference in monthly returns between the two lines (Q1 – Q5) has a T-Statistic of 3.64 and is proven significant at a 95% confidence level, thus we reject the Null Hypothesis that the Average Monthly Return equals 0.
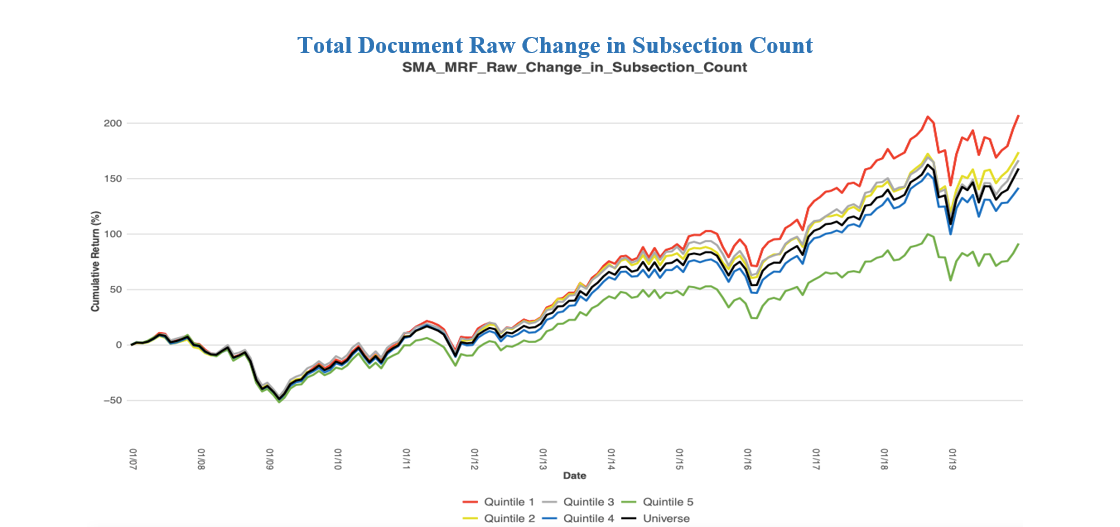
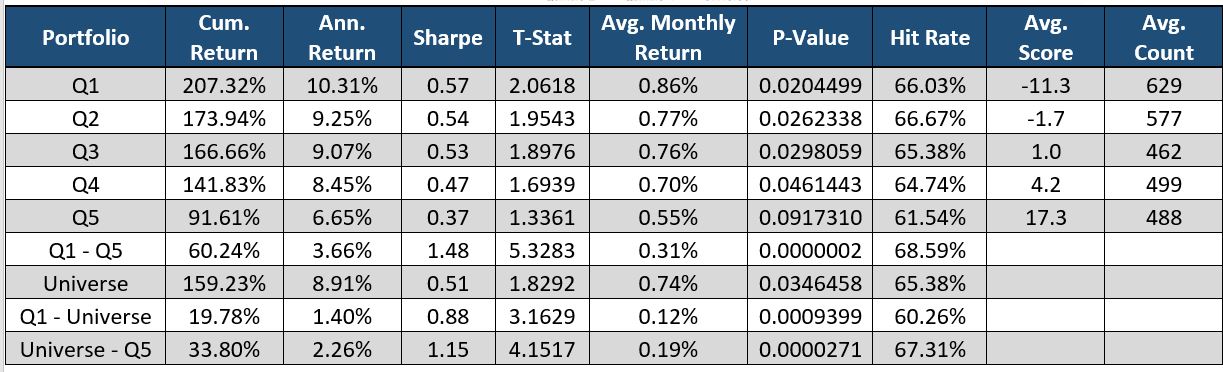
The graph above exemplifies how a change in the number of subsections is an indicative source of future stock returns. This metric is a round integer with a small range so many stocks have the same value, which is why the average count in each bucket is uneven.
Subsections are counted at the Item level and are included if there is a specific topic to discuss. If there are more subsections included in the document (Quintile 5, green line) compared to the previous document, the stock price underperforms its peers. When there is a decrease in the number of subsections (Quintile 1, red line) the stock outperforms its peers.
Subsections are added to a regulatory filing when there’s a specific topic to discuss. Subsection Count and Word Count are correlated because as there are more topics to discuss, there are more words in the document. The addition of a new subsection means there is an event occurring and the company needs to adequately warn its investors. If there are more subsections, then the company has more events that could risk the future value of the company.
The monthly return difference between the two lines (Q1 – Q5) has a high 5.32 T-Statistic and is proven significant at a 95% confidence level. The hit rate, which is the percentage of times the return of the portfolio is greater than 0.00%, is extremely high at 68.59%. This means we reject the Null Hypothesis that the Average Monthly Return equals 0.
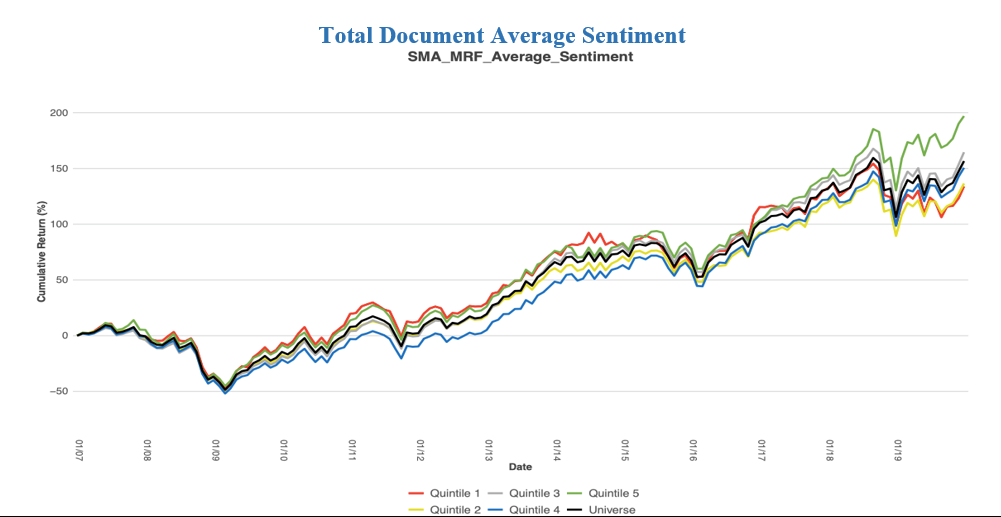
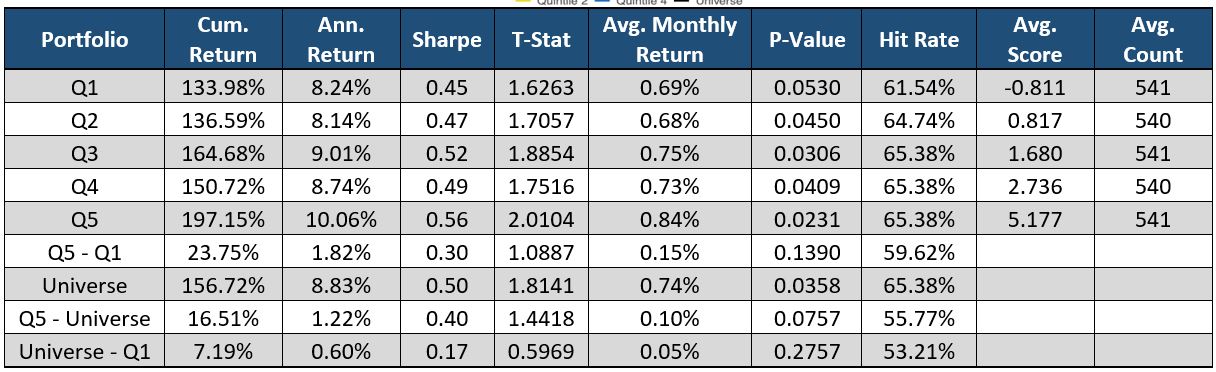
The above graph shows how the Total Document’s average sentiment can be a predictive source. The green line (Quintile 5) has the highest Average Sentiment value and outperforms all other stocks in the universe. Not only does Quintile 5 outperform the rest of the universe, but it also does so with the least amount of risk.
Through SMA’s Natural Language Processing all words in the document are read and assigned a score based on the sentiment of those words. If there is more positive language used throughout the document, the security tends to overperform the market. On the other side, if there is more negative language, the security underperforms its peers.
The red line (Quintile 1) underperforms its peers, but not by a significant amount. Even though the difference between Quintile 5 and Quintile 1 is not proven significant at a 95% confidence level, this factor provides additional alpha on the Long side.

We next looked at the Management Discussion & Analysis section of regulatory filings. This section is unique because of how unstructured it is compared to all other sections. It encompasses how management views the trajectory of the business and future events.
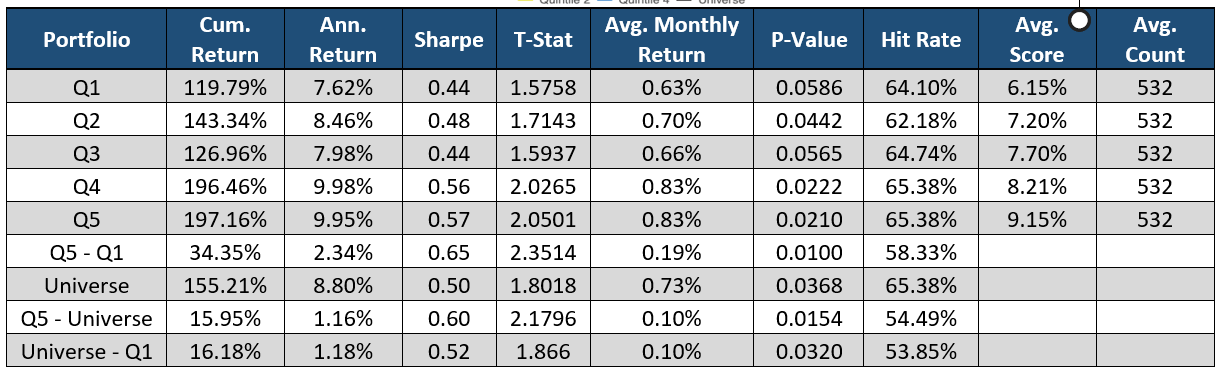
The chart above shows the Quintiles for Percentage of Sentiment Hits. This metric is calculated by dividing Sentiment Hits by Word Count. This is the percentage of the total document that had financial lexicon pertaining to sentiment (either positive or negative).
Quintile 5 (green line) represents the highest Percentage of Sentiment Hits, which outperforms all portfolios. Quintile 1 (red line) underperforms all portfolios. Companies that talk more about its performance in financial terms with sentiment are upfront. This transparency is beneficial for the company as they are forthright with investors. On the other hand, if the MD&A section has a small Percentage of Sentiment Hits that means the company is speaking about information not related to the financial status of the company. These companies don’t provide as much important information or use additional language that is not required. This lack of transparency devalues the company in the eyes of the investors.
The difference between Quintile 5 and Quintile 1 is proven significant at a 95% confidence level and provides a unique source of alpha.
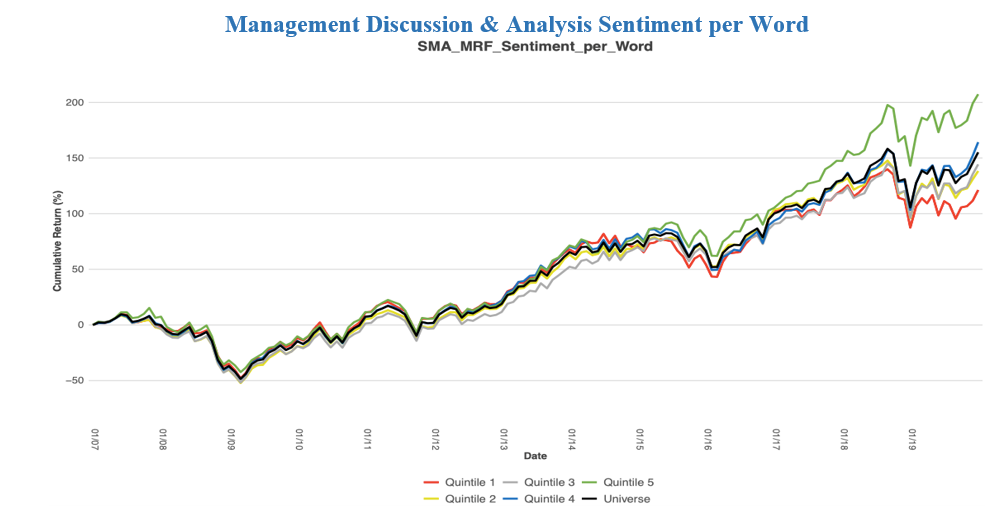
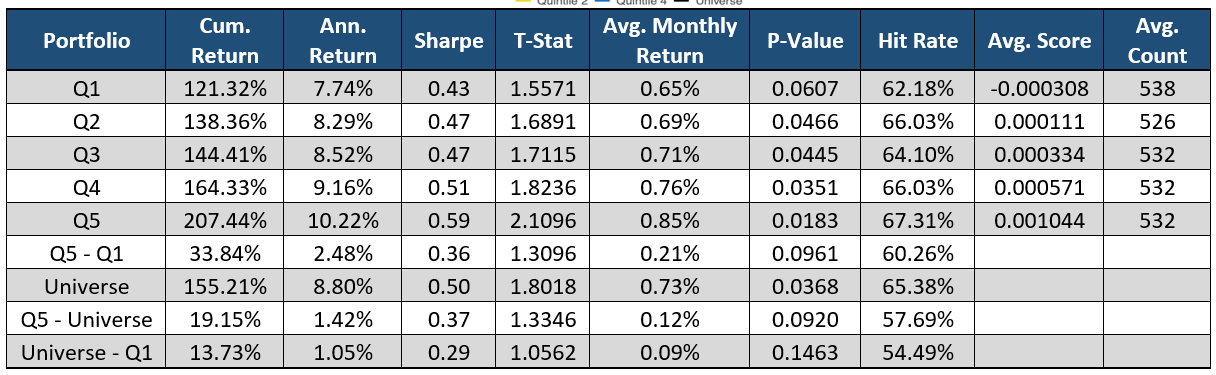
The factor Sentiment per Word is calculated by dividing Sentiment Sum by Word Count. Longer documents are more likely to have an extreme value in Sentiment Sum. The rationale for this is if a document has more words, it is more likely to have more sentiment hits, thus a more extreme value for Sentiment Sum. The Sentiment per Word factor normalizes the magnitude of sentiment based on the length of the document.
Here we see Quintile 5 (green line) outperform and Quintile 1 (red line) underperform all other portfolios. The difference between the two is not proven significant, however this metric still provides insights on the Long side as Quintile 5 has the highest returns with less risk. If a company has a higher Sentiment per Word, then there is more of an upwards outlook on the future of the company and its events. A low Sentiment per Word means the company is negative when speaking about the company’s actions. This would attribute to a lack of confidence in the company’s future.

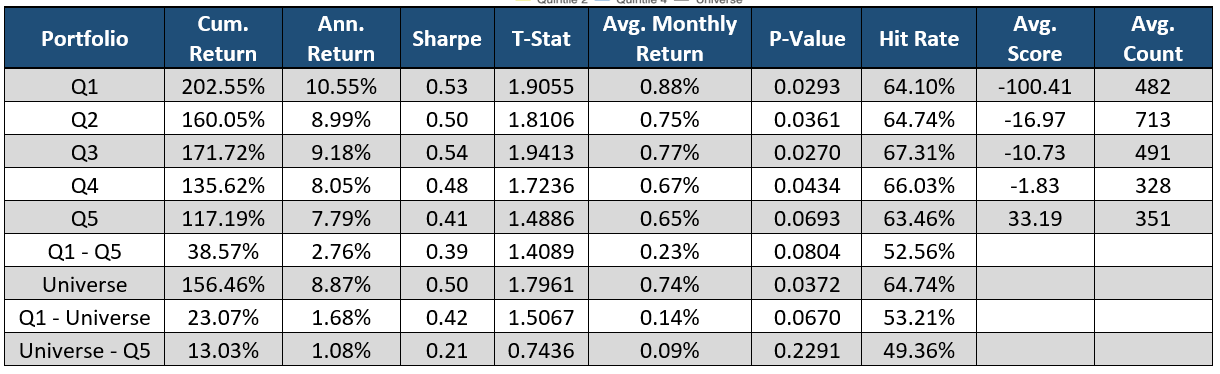
We last looked at the Risk Factors section of regulatory filings. This section generally has a negative tone and states what could go wrong in the company while adequately warning investors.
The factor plotted above, Positive and Negative Hits Difference, is the difference between Positive Hits and Negative Hits. In this graph Quintile 5 (green line) represents filings with a larger number of positive hits than negative hits, which underperforms all other portfolios. Quintile 1 (red line) contains filings that have significantly more negative hits than positive hits, which outperforms all portfolios. Filings with positive language in the Risk Factors section lack truth and transparency which leads to an underperformance. If the company is upfront about the risks of investing and doesn’t put a positive spin on the risks, the investors have more confidence in the company.
Conclusion
Machine Readable Filings is the most advanced and thorough product on the market for drilling into the un-tapped value of textual data in regulatory filings. These filings track how companies evolve and approach strategy in the face of micro and macro trends and the effect of these trends on their short- and long-term goals. While much in these documents do not change over successive quarters and years, the ability to quantify change and the location of change when it exists has been shown to be a predictive factor for stock selection in a portfolio.
Using previous academic research as a guide (Lazy Prices), SMA has shown the predictive nature inherent in changes in regulatory filings. The results presented in this paper show how multiple factors tend to predict future returns in securities and can be a factor for stock selection in a portfolio.
The flexibility of the raw data provided allows subscribers to create an infinite number of derivative factors at the Item, Part, and Total Document level. These factors will continue to be explored as an additional source of alpha.
Although this analysis only included factors at the Total Document level, the Management Discussion & Analysis section, and Risk Factors section, other sections within regulatory filings can provide additional insights into a security’s future return. Furthermore, we expect additional insights to be uncovered using natural language processing to quantify the sentiment of the underlying text at the various levels of the document. These analyses and more will be explored by Social Market Analytics and S&P Global in the future.