This blog will explore the predictive nature of our Futures Twitter based sentiment factors. We calculate real time predictive sentiment on 106 futures. Although factors calculated are identical to equity-based S-factors the NLP is unique because conversations on futures vary significantly based on asset classes. For example, an oil refinery fire is going to be bearish for the owner of the refinery and bullish for the price of oil. To create the most accurate sentiment scores possible we have created separate NLP for Treasuries, Energy, and Agricultural futures. The same Tweet can have a positive and negative sentiment score based on the Topic (XOM & CL_F). We believe we are the only firm using asset class based NLP.
To track the predictive nature of our dataset we create internal reports. One report is the ‘Sanity Report’. This report captures S-Score 15 minutes before settlement of the individual commodity and compares it to the subsequent days return. Sanity value formula is below.

Magnitude and direction of sentiment and return are the basis of the Sanity Score. If a future has a high sentiment score and a large positive return that will have a large positive impact on Sanity Score. If the future has a high sentiment score and a negative subsequent return that will have a negative impact on Sanity score. Aggregating these values provides a good view of overall predictiveness of the S-Score at each point in time.
We calculate Sanity values for the following commodities:

A cumulative Sanity chart from Jan 2019 to current is below.
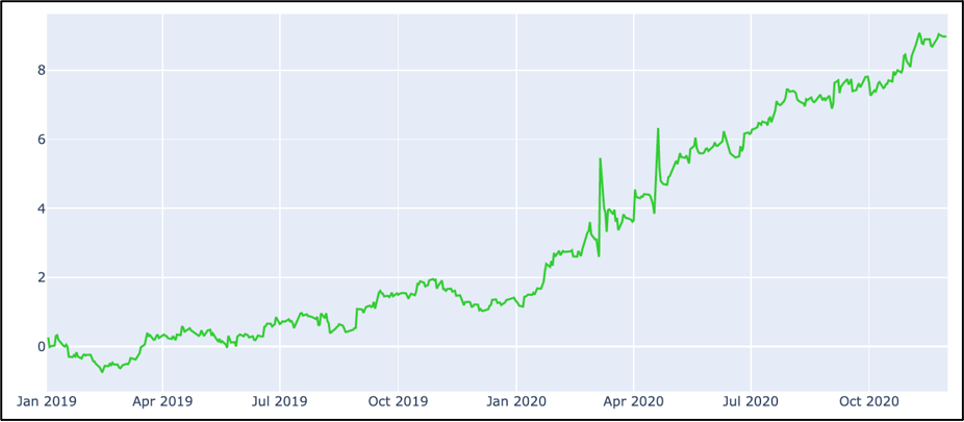
This chart shows that SMA Futures S-Scores are consistently predictive. Adding other factors such as S-Dispersion and SV-Score can increase the predictability of the dataset. To learn more about SMA Futures data please ContactUs@SocialMarketAnalytics.com.